



Scraping is just the act of collecting something by separating it from its substance. Take the Internet out of the equation; data scraping can be as simple as going to a real estate listing (or magazine) and taking notes (collecting and importing data).
But data scraping has been growing wild lately and getting quite useful for things like market research, data mining, and SEO. With the Internet and automation, data scraping tools would automatically extract data such as pricing, pictures, contact info, and more from any website on the Internet.
So what is data scraping? In the most general term, it is the process of extracting information from a target data source. Data scraping is also referred to as data extraction.
Other Similar Terms:
- What is web scraping? It refers to the process of extracting “valuable” information, specifically from a website.
- What is data crawling? This term is similar to extracting data, but the purpose is different. Search engines use crawlers (bots) to find and index Internet content.
- What is data mining? The process of identifying patterns in data sets with techniques like statistics, database, and machine learning.
Web scraping follows the simple process > Connect to an HTTP site > Collect its data > Create a Structure.


Is Data Scraping Illegal?
Data scraping is not illegal. Web content is available on a site for a reason: to be accessible by visitors. But is a bot a visitor as well? Bots are rarely visiting a site to read and learn (as you would); their purpose is different; they are there only to extract data. So the legal context is different.
What you do with the data is what can get you into trouble.
- Stealing data (reusing content or downloading copyright material) is illegal.
- It is also illegal to extract data that is not publicly available.
Why is Data Scraping Challenging?
Companies don’t want their unique content to be so easily collected and reused for other purposes, such as getting studied “spied” by the competition, market research, etc. Additionally, web scraping tools send too many requests in a single blow that may slow down the entire website, affecting other human visitors’ traffic.
These companies want their end-customers to consume their website content, not a particular bot scraping, collecting information, and making the site slower— so they use techniques to limit access and block these bots.
Technically, any content that a typical website visitor can access, it can also be scraped by a bot.
But companies will attempt to find the right balance between giving access to a regular visitor and not affecting its experience and blocking out web scraping attempts from a bot.
Here are the usual data protection strategies:
- Limit the rate of requests. Websites protect themselves from web scraping bots by limiting the rate of their incoming requests. The average speed a regular human visitor can click through a website is not the same as a computer would. Computers can send requests at a much larger and faster rate than a regular visitor. So, a content protection tool would limit the maximum number of requests that a specific source (IP address) can make within a timeframe.
- Changing the HTML markup code regularly. Websites protect themselves from web scraping by regularly changing some elements within the HTML markup code. The web scraping bot uses a set of instructions to go across a website’s content and extract information. When a web scraping bot faces an inconsistent and randomized HTML code, it will still be capable but will have a very difficult time.
- Requiring CAPTCHAs and image-based CAPTCHA challenges. Prove you are not a robot! These are prevalent messages all across the Internet now. Their mission is to stop web scraping bots and spammers from trying to harvest data automatically. Web scrapers use headless browsers (no GUI) to move faster at the command line level. Challenges like CAPTCHAs, break this “automated” traffic by bringing the visitor back to the graphical-level interface. These visual challenges are difficult (if not impossible) for computers to solve.

Tips to Bypass Website Security Systems.
Websites would use a combination of the anti-scraping bot tools and techniques, mentioned in the previous section. For example changing HTML markup and visual challenges can be quite effective against web scraping.
But the number one challenge is rate limiting by IP.
You can’t access a target website as many times as you want and as fast as you want. If your computer gets its IP blocked, it might get also blacklisted, and you will be unable to connect to the target site (and possibly to a lot more sites within the same IP subnet).
1. Use a Proxy!
A proxy acts as an intermediary between you and the target. There is no direct contact with the target— so all requests that you send will go first through the proxy. The proxy will re-package the request and label it as its own. So, in reality, the website will receive and process the proxy’s IP— and not yours.
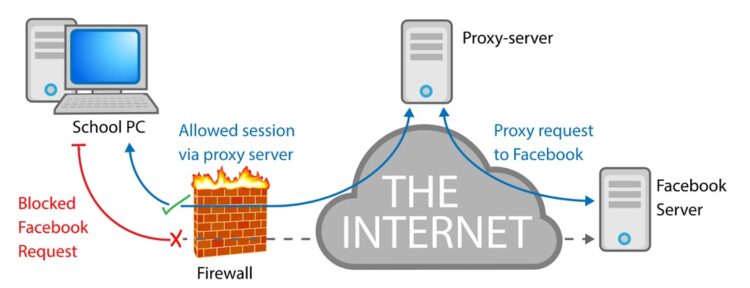

A proxy solves the problem!
It makes data scraping undetectable and scalable. To accomplish this, web scrapers have to use an extensive proxy list or number of proxy servers. Proxies can make web scraping look unique and human.
An IPv6 proxy, for example, allows web scrapers to automatically rotate between IPs from a large pool for every single request. A proxy service provides an entire proxy network for you to rotate IPs and assign a new random proxy for every request.
Every IP request is like a unique device within a separate subnetwork. So it becomes undetectable and unblockable by the target.
2. Avoid CAPTCHAs.
CAPTCHAs have their benefits; they avoid websites getting hammered by nasty spammers. Getting their traffic bogged down by a single source from a thousand requests is no fun, and it’s close relative to a DoS (Denial of Service) attack.
Some CAPTCHAs’ level of vision and audio recognition problem-solving skills are still not found in your everyday robot.
There are some services offered via APIs that use Machine Vision mechanisms to try to solve these challenges. Still, if you are doing automatic web scraping, you’ll likely need to solve CAPTACHAs as you would typically do if you were browsing.
Final Words.
They say: “Data is the new oil,” and so, “Data scraping is the drilling tool.”
Data scraping can be beneficial for you and your business if you know how to do it responsibly. Take the data that is already publicly available, collect it (without compromising a destination), and provide it some structure. Running some AI and ML algorithms on that data— the sky’s the limit. You could study market trends, gain insights, and gain a competitive advantage.
Always
Web scrape responsibility!
Cheers!